
 14.jūnijā Latvijas tiesību institūts rīkoja Amsterdamas universitātes (Nīderlande) pasniedzēja Mihņa Konstantinesku (Mihnea Constantinescu), PhD, Finanses, vieslekciju par mašīnmācīšanos un mākslīgo intelektu, kā arī to radītajiem ekonomiskajiem un juridiskajiem izaicinājumiem „Codes, Cases and Contracts: Navigating the AI Frontier”. Vizītes ietvaros pasniedzējs apmeklēja arī Augstāko tiesu un vēlāk sagatavoja šo rakstu speciāli „Augstākās Tiesas Biļetenam”.
14.jūnijā Latvijas tiesību institūts rīkoja Amsterdamas universitātes (Nīderlande) pasniedzēja Mihņa Konstantinesku (Mihnea Constantinescu), PhD, Finanses, vieslekciju par mašīnmācīšanos un mākslīgo intelektu, kā arī to radītajiem ekonomiskajiem un juridiskajiem izaicinājumiem „Codes, Cases and Contracts: Navigating the AI Frontier”. Vizītes ietvaros pasniedzējs apmeklēja arī Augstāko tiesu un vēlāk sagatavoja šo rakstu speciāli „Augstākās Tiesas Biļetenam”.
Ievads
Mašīnmācīšanās un mākslīgā intelekta ceļš uz kļūšanu par mūsu acu, ausu un smadzeņu digitālajiem paplašinājumiem ir bijis ilgs un pakāpenisks process, ko iezīmē gadu desmitiem ilga pakāpeniska attīstība, līdz tika sasniegts pašreizējais veiktspējas līmenis. Šī tehnoloģiskā evolūcija sākās lēnām, kad 20.gadsimta 50. un 60.gados agrīnie mākslīgā intelekta pētījumi izveidoja teorētiskos pamatus, kas tomēr pārsvarā bija bez praktiska pielietojuma. Gadu desmitiem ilgi nozare attīstījās ar pārtraukumiem, optimisma periodiem mijoties ar „mākslīgā intelekta ziemām”, kad progress šķita apstājies. Sarežģītāku sensoru – mūsu digitālo acu un ausu – attīstība bija līdzīgi pakāpeniska, to agrīnajām versijām esot dārgām un ierobežotām savās iespējās. Lai gan skaitļošanas jauda auga eksponenciāli, kā to paredzēja Mūra likums, tomēr pagāja gadu desmiti, līdz tika sasniegts tāds līmenis, kas nepieciešams sarežģītām mākslīgā intelekta lietojumprogrammām.
Iespējams, vissvarīgākais bija tas, ka algoritmu, kas spēj atdarināt cilvēka domāšanas aspektus, pilnveidošana bija komplicēts process, kas balstījās uz vairāku paaudžu pētījumiem dažādās disciplīnās. Tikai pēdējos gados redzam, kā šīs dažādās attīstības līnijas saplūst un nobriest, beidzot sasniedzot tādu stadiju, kad mākslīgā intelekta sistēmas var jēgpilni papildināt cilvēka spējas. Pēc šī ilgā nobriešanas perioda šodien mums ir mākslīgais intelekts, kurš var redzēt (izmantojot progresīvu datoru redzi), dzirdēt un runāt (izmantojot sarežģītu runas atpazīšanu), kā arī domāt (izmantojot sarežģītus datu analīzes un lēmumu pieņemšanas algoritmus) līdzās mums, paplašinot robežas tam, ko mēs varam uztvert, saprast un paveikt. Mākslīgais intelekts arvien vairāk ietekmē profesionālo darbību, sākot no jurisprudences līdz medicīnai, no attēlu klasifikācijas līdz tiesvedību iznākumu prognozēšanai.
Formāli mašīnmācīšanās ir mākslīgā intelekta apakšnozare, kura koncentrējas uz algoritmu un statistisko modeļu izstrādi, atļaujot datorsistēmām uzlabot savu sniegumu konkrētu uzdevumu izpildē caur mācīšanos. Šie modeļi ir izstrādāti, lai atpazītu datu (skaņas, attēlu vai teksta) šablonus un tos pielietotu prognozēšanā, optimālu izvēļu veikšanā, ņemot vērā sarežģītus izmaksu un ieguvumu profilus, kā arī lai iepriekš paredzētu rezultātus individuālā vai grupu vidē.
Mašīnmācīšanās būtībā ir dažādu parametru novērtēšana. Kad mēs sakām, ka modelis „mācās”, mēs domājam procesu, kurā modeļa parametri tiek pielāgoti, lai tie labāk atbilstu novērotajiem datiem. Šis process ir vairāk līdzīgs statistiskai optimizācijai nekā cilvēka mācīšanās procesam, tāpēc termina „mācīšanās” lietošana šajā kontekstā ir neprecīza. Bet ko tieši mašīnas mācās?
Vai mašīnas var mācīties?
Šajā raksta sadaļā kā piemērs tiks aplūkota mašīnmācīšanās modeļa lietošanas lietderība un riski, novērtējot algu taisnīgumu. Šis piemērs izgaismos svarīgu mijiedarbību starp mašīnmācīšanās modeļa, kas saprot pasauli kā 0 un 1 virknes, tehniskajiem aspektiem un juridisko praksi, kur vārdiem ir subjektīva nozīme, ko veido klausītāja morālās vērtības.
Pateicoties spējai analizēt milzīgu datu apjomu un identificēt šablonus un likumsakarības, kas cilvēka acij varētu paslīdēt garām, mašīnmācīšanās modeļi piedāvā daudzpusīgu rīku kopumu algu taisnīguma pārbaudes veikšanā. Kamēr šāda manuāla analīze aprobežotos vien ar dažiem apskatāmajiem gadījumiem vai paļautos uz plašiem vispārinājumiem, labi izstrādāts mašīnmācīšanās modelis var apstrādāt tūkstošiem vai pat miljoniem algu datu punktu, ņemot vērā daudzus mainīgos lielumus, piemēram, konkrētās personas pieredzi, izglītību un snieguma rādītājus, kā arī demogrāfiskos faktorus. Šī visaptverošā pieeja ļauj niansētāk izprast algu struktūras organizācijā vai nozarē, potenciāli atklājot smalkas neobjektivitātes vai neatbilstības, ko tradicionālās metodes bieži nepamanītu.
Šo modeļu efektivitāte arī padara iespējamu veikt regulāras, liela mēroga analīzes, kas būtu pārāk laikietilpīgas un dārgas, ja tās veiktu tikai cilvēki. Tomēr šo rīku jauda ir saistīta ar ievērojamiem riskiem. Ja modeļa pamatā esošie pieņēmumi ir kļūdaini vai ja izmantotie dati nav attiecināmi uz plašāku iedzīvotāju grupu, rezultāti būs maldinoši vai, vēl ļaunāk, tie pastiprinās jau pastāvošos aizspriedumus. Piemēram, modelis, kurš izmanto vēsturiskus algu datus, varētu turpināt pagātnes diskriminējošu praksi, ja šī prakse ir iestrādāta izmantojamo datu kopā. Tāpat, ja noteiktas iedzīvotāju grupas ir nepietiekami pārstāvētas modeļa izmantotajos datos, tad modeļa secinājumi par algu taisnīgumu var būt izkropļoti. Modeļa izdarīto pieņēmumu stingra pārbaude, datu reprezentativitātes rūpīga pārbaude un rezultātu kritiska izvērtēšana plašākā sociālā un ētiskā kontekstā prasa, lai tiesību speciālists, kurš strādā ar konkrēto modeli, vispārīgi izprastu modeļa tehniskos ierobežojumus, ņemot vērā pastāvošo tiesisko ietvaru.
Ja apskata mašīnmācīšanos, tās modelis ir līdzīgs tiesiskajam regulējumam vai tiesību aktam. Tāpat kā tiesību akts vienkāršo sarežģītas sociālās norises noteikumu kopumā, mašīnmācīšanās modelis vienkāršo realitāti matemātiskā attēlojumā, kurš domāts, lai parādītu būtisko, vienlaikus ignorējot nebūtisko. Piemēram, algu prognozēšanas modelis, līdzīgi kā lineārās regresijas piemērs zemāk, ir līdzīgs soda noteikšanas vadlīnijām, kas ņem vērā dažādus faktorus, lai noteiktu atbilstošu sodu. Jau šeit mēs redzam mašīnmācīšanās modeļa konceptuālos ierobežojumus – realitāti veido konkrētais jautājums. Ja mērķis ir izprast taisnīgumu (ko galu galā definē tiesību speciālists), tad būtiskais un nebūtiskais tiek definēts šī mērķa kontekstā. Bieži gadās, ka nebūtiskais (izslēgts no matemātiskā modeļa efektivitātes apsvērumu dēļ) galu galā izrādās būtisks, taču nav ticis ņemts vērā.
Mainīgie lielumi ir mūsu modeļa ievaddati, līdzīgi kā tiesu lietas apstākļi un fakti. Mūsu piemērā par algu taisnīgumu mainīgie lielumi varētu ietvert konkrētās personas darba stāžu, izglītības līmeni vai darba izpildes rādītājus. Tāpat kā atšķirīgi tiesu lietas apstākļi var ietekmēt lietas iznākumu, šie mainīgie lielumi ietekmē modeļa prognozi. Līdz ar mainīgajiem lielumiem mums ir arī parametri. Tie ir modeļa sastāvdaļas, kas tiek aprēķinātas no datiem, līdzīgi kā esošie precedenti tiesu praksē. Tāpat kā juridiskie precedenti laika gaitā tiek pilnveidoti ar jaunām tiesu lietām, tā arī šie parametri ar laiku tiek pielāgoti, modelim saskaroties ar lielākiem datu apjomiem.
Process, kurā tiek noteikti labākie parametri modelim, tiek saukts par apmācību vai mācīšanos. Tas ir līdzīgs juridiskās izglītības procesam un pieredzes iegūšanai tiesas zālē, kur cilvēks apgūst, kā iztulkot un piemērot likumus dažādās situācijās. Kad apmācīts modelis tiek piemērots jauniem datiem, lai novērtētu rezultātu, tas izsaka prognozi. Tas ir līdzīgi, kā piemērot spēkā esošus likumus un pastāvošu judikatūru jaunas lietas izskatīšanai tiesā, lai noteiktu tās ticamāko iznākumu.
Te ir lietderīgi apskatīt vienkāršu lineārās regresijas modeli, vienu no vienkāršākajiem mašīnmācīšanās ietvariem, lai prognozētu algu, balstoties uz darba stāža gadiem. Šis modelis norāda, ka starp darbinieka pieredzes gadu skaitu un viņa algu pastāv sakarība, kas tiek uzskatīta par lineāru (skatīt 1.attēlu). Matemātiskā formula jau faktiski strukturē realitāti attiecībā uz šo sakarību un norāda, ka būtiskais mainīgais lielums, kurš nosaka algas apmēru, ir darba pieredzes gadu skaits.
Ņemot vērā, ka mēs sagaidām, ka lielāks pieredzes gadu skaits būs saistīts ar lielāku algu, parametrs β₁ būs pozitīvs skaitlis, bet tas ir jāaprēķina, izmantojot faktiskos datus, tas ir, modelis ir jāapmāca. „Alga” ir atkarīgais mainīgais, ko mēs cenšamies prognozēt, savukārt „Pieredzes gadi” ir neatkarīgais mainīgais (saukts arī par argumentu). Galvenie parametri ir:
- β₀ jeb y-krustpunkts: šī ir pamata alga bez pieredzes;
- β₁ jeb slīpums: šis ir algas pieaugums par katru pieredzes gadu;
- ε ir kļūdas apzīmējums, tas ir, kaut kas, ko mūsu modelis nespēj izskaidrot.
Šajā modelī β₀ un β₁ ir parametri, kurus modelim jāidentificē. Matemātiski šis modelis tiek izteikts kā:
Alga = β₀ + β₁ * (Pieredzes gadi) + ε
„Mācīšanās” mašīnmācīšanās kontekstā nozīmē procesu, kurā tiek atrastas labākās vērtības modeļa parametriem (mūsu gadījumā β₀ un β₁), lai veiktu precīzas algu prognozes. Šis process tiecas padarīt modeļa prognozes pēc iespējas tuvākas faktiskajām algām mūsu datu kopā.
Modelis sākas ar sākotnējiem minējumiem par β₀ un β₁. Tie varētu būt nejauši skaitļi vai nulles, bet visbiežāk tie būs Algas un Pieredzes gadu vidējie rādītāji. Izmantojot šos sākotnējos lielumus, modelis prognozē algas visiem darbiniekiem datu kopā un salīdzina savas prognozes ar faktiskajām algām. Starpība starp prognozētajām un faktiskajām algām tiek saukta par „kļūdu”, kas mūsu modelī apzīmēta kā ε.
Pamatojoties uz šīm kļūdām, modelis nedaudz maina β₀ un β₁, lai mēģinātu samazināt visu kļūdu summu piemērā. Šis process tiek atkārtots daudzas reizes, katru reizi modelim cenšoties kļūt nedaudz labākam algu prognozēšanā. Šis process turpinās, līdz uzlabojumi kļūst ļoti mazi vai ir veikts iepriekš noteikts uzlabošanas mēģinājumu skaits.
Šī procesa mērķis ir atrast β₀ un β₁ vērtības, kas rada vismazāko kopējo kļūdu algu prognozēs. Tehniskos jēdzienos runājot, to sauc par „optimizāciju” – labākā risinājuma atrašanu problēmai. Šeit izmantotā konkrētā optimizācijas veida mērķis ir „minimizēt” (padarīt pēc iespējas mazāku) visu prognožu kvadrātisko kļūdu summu. Izejot cauri šim mācīšanās procesam, modelis pakāpeniski uzlabo savu spēju prognozēt algas, balstoties uz pieredzes gadiem. Galīgās β₀ un β₁ vērtības atspoguļo to, ko modelis ir „iemācījies” par sakarību starp pieredzi un algu dotajā datu kopā.
Skaitlisks piemērs parādīs, kā to var izmantot. Pieņemsim, ka modeļa apmācības beigās tiek novēroti šādi parametri:
Alga = 1000 + 50 * (Pieredzes gadi)
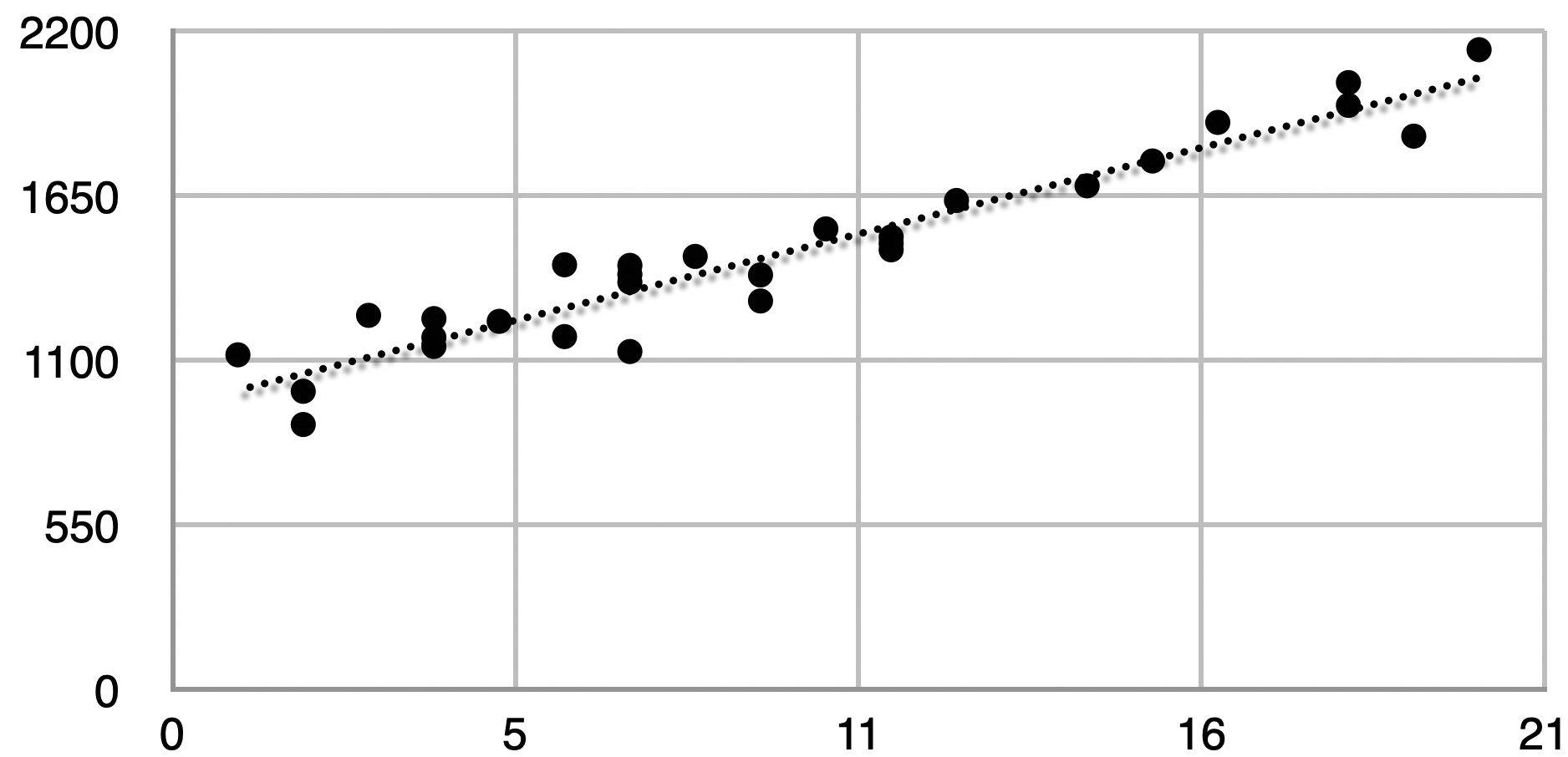 Tad var prognozēt Algas vērtību kā Pieredzes gadu funkciju, vienkārši aizstājot pieredzes gadu skaitu formulā un veicot aprēķinus. Jauns skolas absolvents bez pieredzes nopelnītu 1000 eiro mēnesī (1000 + 50*0), savukārt pieredzējis profesionālis ar 10 gadu pieredzi nopelnītu 1500 eiro mēnesī (1000 + 50*10). 1. attēls parāda piemēru (kā izkliedes diagrammu) un apmācīto modeli kā punktēto līniju.
Tad var prognozēt Algas vērtību kā Pieredzes gadu funkciju, vienkārši aizstājot pieredzes gadu skaitu formulā un veicot aprēķinus. Jauns skolas absolvents bez pieredzes nopelnītu 1000 eiro mēnesī (1000 + 50*0), savukārt pieredzējis profesionālis ar 10 gadu pieredzi nopelnītu 1500 eiro mēnesī (1000 + 50*10). 1. attēls parāda piemēru (kā izkliedes diagrammu) un apmācīto modeli kā punktēto līniju.
Mašīnmācīšanās ierobežojumi
Vai varam izmantot šo modeli, lai novērtētu algu sadalījuma taisnīgumu uzņēmumā? Pastāv daudz bažu, kas saistītas gan ar to, kā modelis darbojas, gan ar tā pamatā esošajiem datiem. Tehniskā žargonā runājot, daudziem modelēšanas pieņēmumiem jābūt patiesiem, lai modeļa parametri atspoguļotu sakarību starp abiem mainīgajiem lielumiem. Modeļa ierobežojumi kļūst ātri acīmredzami, tiklīdz mēs pamanām, ka atalgojuma apmērs ir saistīts ar daudziem citiem mainīgajiem lielumiem, kā, piemēram, izglītības gadiem, darba stāžu uzņēmumā, sniegumu, ko rāda ikgadējais novērtējums utt. Mēs esam izslēguši no matemātiskā attēlojuma svarīgus mainīgos lielumus, kuriem ir nozīme algas apmēra taisnīguma noteikšanā.
Mašīnmācīšanās jomā izslēgto mainīgo lielumu neobjektivitāte ir kritisks jēdziens, ar ko var vilkt skaidras paralēles juridiskajā argumentācijā. Iedomājieties tiesnesi, kurš sarežģītā lietā balsta savu lēmumu tikai uz vienu pierādījumu, ignorējot citus būtiskus faktorus. Šāda pārmērīga vienkāršošana varētu novest pie kļūdaina sprieduma, līdzīgi kā izslēgto mainīgo lielumu neobjektivitāte var izkropļot mašīnmācīšanās modeļa rezultātus. Algu taisnīguma piemēra kontekstā iepriekš apskatītais modelis prognozē taisnīgu atalgojumu, balstoties vienīgi uz darba pieredzes ilgumu. Lai gan pieredze neapšaubāmi ir būtiska, šāda pieeja ar vienu mainīgo neņem vērā citus ļoti svarīgus faktorus, piemēram, izglītības līmeni, darba sniegumu vai specifiskas prasmes – līdzīgi kā tiesnesis, kas ignorē svarīgākās liecības vai pierādījumus.
Šādas būtisku faktoru ignorēšanas sekas ir nopietnas: modelis uzskatīs, ka algu atšķirība, kas balstīta tikai uz pieredzi, ir taisnīga, kaut patiesībā tā maskē diskriminējošo praksi, kas saistīta ar piekļuvi izglītībai vai snieguma novērtēšanas neobjektivitāti. Tāpat kā taisnīgam juridiskam procesam nepieciešama visu būtisko apstākļu un kontekstu izvērtēšana, taisnīgam algoritmam jāņem vērā visaptverošs mainīgo lielumu kopums, kas var ietekmēt rezultātu. Būtisku mainīgo lielumu ignorēšana ne tikai samazina modeļa precizitāti, bet var arī turpināt vai pat pastiprināt esošos aizspriedumus, novedot pie lēmumiem, kuri šķiet balstīti uz datiem un objektīvi, bet patiesībā ir fundamentāli kļūdaini. Tāpēc, izstrādājot modeļus tik jutīgiem pielietojumiem kā algu taisnīguma analīze, visu būtisko mainīgo lielumu iekļaušana ir ļoti līdzīga rūpīgam juridiskam procesam, kas nodrošina, ka visi būtiskie pierādījumi tiek uzrādīti un izvērtēti pirms sprieduma taisīšanas.
Kā mēs varam zināt, kuri mainīgie lielumi ir būtiski?
Reālās dzīves pielietojumu sarežģītība: Trūkstošie mainīgie lielumi un nezināmās cēloņsakarības
Lai gan viena mainīgā lieluma algas modelis kalpo kā pamācošs piemērs, tā struktūra, izmantojot tikai vienu mainīgo, ir apzināti vienkāršota, lai izgaismotu dziļās problēmas, ar kurām saskaras mašīnmācīšanās pielietošana reālajā dzīvē. Praksē mēs bieži atrodamies kontekstā, kas līdzinās kriminālizmeklēšanai ar nepilnīgiem pierādījumiem un neskaidru saistību starp esošajiem apstākļiem. Atšķirībā no iepriekš minētā vienkāršotā piemēra reālās dzīves scenāriji reti piedāvā skaidru un visaptverošu visu būtisko mainīgo lielumu sarakstu.
Reālistiskākā algu taisnīguma modelī mums jāņem vērā pieredze, izglītība un snieguma rādītāji, kā tas jau noskaidrots ekonomikas un socioloģijas literatūrā. Tomēr mēs varētu palaist garām tādus būtiskus faktorus kā konkrētās personas sociālos kontaktus un tīklošanās iespējas, neapzinātu neobjektivitāti snieguma novērtējumos vai karjeras agrīno izvēļu ilgtermiņa sekas. Reizēm mēs zinām, ka kāds mainīgais lielums ir būtisks, tomēr mums var pietrūkt iespēju iegūt par to datus. Lai situāciju padarītu vēl sarežģītāku, cēloņsakarības starp šiem mainīgajiem lielumiem bieži ir savstarpēji saistītas, līdzīgi kā sarežģītas juridiskas lietas apstākļu sarežģītais tīkls. Cilvēka izglītība var ietekmēt viņa darba sniegumu, kas savukārt ietekmē viņa algu, bet viņa ģimenes fons varētu būt ietekmējis viņa izglītības iespējas jau pašā sākumā. Šo cēloņsakarību tīklu ir grūti atšķetināt un vēl grūtāk kvantificēt modelī. Risks šeit ir daudzpusējs: mēs varam izlaist mainīgos lielumus, kas ir būtiski taisnīgu lēmumu pieņemšanai, mēs varam netīši iekļaut mainīgos lielumus, kuri iebūvē sabiedrības aizspriedumus mūsu šķietami objektīvajā modelī, vai mēs varam iekļaut mainīgos lielumus, kuri vispār nav būtiski. Šo izaicinājumu pastiprina fakts, ka mainīgo lielumu nozīmīgums un cēloņsakarības var mainīties laika gaitā vai atšķirties dažādos kontekstos, līdzīgi kā juridiskie precedenti var attīstīties vai tikt piemēroti atšķirīgi dažādās jurisdikcijās.
Pat labi domāti mēģinājumi izveidot taisnīgus un visaptverošus mašīnmācīšanās modeļus var neizdoties, potenciāli novedot pie lēmumiem, kas šķiet balstīti uz datiem un objektīvi, bet patiesībā ir fundamentāli kļūdaini vai neobjektīvi. Šī realitāte uzsver kritisko nepieciešamību pēc pastāvīgas pārbaudes, daudzveidīgiem skatījumiem modeļu izstrādē un pazemīgas mūsu modeļu ierobežojumu atzīšanas – īpaši, kad tie tiek izmantoti, lai pieņemtu nozīmīgus lēmumus, kas ietekmē cilvēku dzīvi un iztiku.
Kā jau pārrunāts manas vieslekcijas laikā, šie jautājumi var nonākt tiešā pretrunā ar galvenajiem tiesību principiem. Piemēram, recidīvisma noteikšanas algoritms „COMPAS” izmantoja klasifikācijas modeli, lai prognozētu gan recidīvisma iespējamību, gan pakāpi ASV. Modelī izmantotie mainīgie lielumi tika atlasīti, balstoties uz vairākiem akadēmiskiem pētījumiem, taču nepietiekami ņēma vērā sociālo kontekstu un cēloņsakarības tā prognozēšanā. Algoritms uzskatīja katru mainīgo lielumu par neatkarīgu prognozētāju, neņemot vērā sarežģīto sociālo, ekonomisko un sistēmisko faktoru mijiedarbību, kas veicina noziedzīgu uzvedību un recidīvismu. Sistēma varēja identificēt saikni starp bezdarbu un augstākiem recidīvisma rādītājiem, neapsverot bezdarba pamatā esošos cēloņus noteiktās kopienās. Mašīnmācīšanās algoritms iemācījās datu šablonu, bet tas nebija spējīgs saprast, kas to izraisa. Neobjektīvais paraugs noveda pie tā, ka indivīdi no visvairāk pārstāvētām grupām izmantotajos datos tika prognozēti kā augsta riska indivīdi ar lielāku varbūtību atkārtot noziegumus, neatkarīgi no faktiski novērotās viņu atkārtotas noziedzības iespējamības.
Datu kvalitātei ir vienlīdz svarīga loma. Ir būtiski nodrošināt, lai datu kopa būtu reprezentatīva un brīva no atlases neobjektivitātes. Ja pagātnes diskriminējošā prakse ietekmēja pieņemšanu darbā, paaugstināšanu amatā un algu līmeņus, modelis var vienkārši „iemācīties” šos aizspriedumus un atspoguļot tos parametru vērtībās. Tas pats attiecas uz recidīvisma noteikšanas modeli.
Juridiskajā kontekstā tas varētu ietvert plašu judikatūras, tiesību aktu un juridisko dokumentu datubāzu veidošanu, vienlaikus nodrošinot, ka tie pārstāv daudzveidīgu juridisko scenāriju un rezultātu klāstu. Taču atkarībā no konkrētā jautājuma tas varētu ietvert arī esošās datu kopas paplašināšanu ar būtiskiem, bet ne viegli pieejamiem datu kopumiem (piemēram, ienākumi, ieguldījumi vai nodokļu maksājumi). Reizēm šādi datu kopumi var nebūt publiski pieejami, vai, pat ja tie ir pieejami, tie var būt nesamērīgi dārgi.
Juridiskā robeža
Juridiskās profesijas piedzīvo strauju jauna veida mākslīgā intelekta rīku – Lielo Valodas modeļu – ieviešanu. Šīs digitālās konstrukcijas, kuras ir apmācītas, par pamatu ņemot milzīgus teksta apjomus, spēj apstrādāt un ģenerēt cilvēkiem līdzīgu valodu iepriekš nepieejamā līmenī. Līdzīgi kā apdāvināts juridiskais praktikants, šie modeļi var ātri pārskatīt un izprast milzīgus teksta apjomus. Tie jau ir atraduši pielietojumu juridiskajā jomā, tomēr ne bez ievērojamiem riskiem un trūkumiem.
Līgumu analīzē Lielie Valodas modeļi piedāvā ātras dokumentu pārskatīšanas iespējas. Kā digitālais palīgs Lielie Valodas modeļi spēj apstrādāt vairāk nekā 100 lappušu garu līgumu tikai dažās sekundēs, izceļot potenciāli problemātiskas līguma klauzulas vai neatbilstības. Taču šīs digitālās valodas konstrukcijas runā labāk, nekā domā. Modeļa izpratnei, lai gan tā ir plaša, trūkst niansētas juridiskā konteksta izpratnes, kas parasti piemīt pieredzējušam advokātam. Pastāv reāls risks palaist garām smalkas, bet kritiskas detaļas, modeļa ieteikumi netīši atspoguļo aizspriedumus, kas pastāv tā izmantotajos datos, potenciāli turpinot novecojušas vai diskriminējošas juridiskās prakses.
Juridiskajā izpētē šie modeļi palielina juristu spēju atrast atbilstošas tiesu lietas un tiesību aktus. Tie var ātri identificēt datu šablonus tūkstošos juridisko dokumentu, atklājot precedentus, kas varētu būt palikuši nepamanīti gadu desmitiem ilgā juridiskajā praksē. Tomēr pastāv risks, ka modelis var nepareizi interpretēt juridiskos jēdzienus, kas var novest pie kļūdainiem pētījumu rezultātiem un apdraudēt veselas juridiskās stratēģijas.
Šo modeļu izmantošana tiesu lietu iznākumu prognozēšanā, iespējams, ir visstrīdīgākā. Analizējot datu šablonus iepriekšējās tiesu lietās, šie rīki piedāvā ieskatus iespējamos spriedumos. Šī pieeja bīstami tuvojas tiesību sarežģītības reducēšanai līdz vienkāršām statistiskām varbūtībām. Tā neņem vērā katras lietas unikālos apstākļus, tiesību iztulkošanas mainīgo dabu un cilvēka sprieduma fundamentālo lomu juridiskajā procesā. Pastāv reāla iespēja, ka pārmērīga paļaušanās uz šādām prognozēm var novest pie pašpiepildošas pareģošanas, kur modeļa rezultāts ietekmē juridiskās stratēģijas tādos veidos, kas patiesībā palielina tā prognožu piepildīšanās iespējamību.
Uzņēmumu padziļinātas izpētes procesos šo modeļu spēja ātri apstrādāt milzīgus dokumentācijas apjomus ir īpaši pievilcīga. Tādos scenārijos kā, piemēram, uzņēmumu apvienošanās, kur laiks un ātra rīcība bieži ir svarīgi faktori, šie rīki varētu ievērojami paātrināt dokumentu izskatīšanas procesu. Tomēr ir arī pamanāmi daudzi trūkumi. Lietotāji ziņo par gadījumiem, kad modeļi ir palaiduši garām kritisku informāciju, kas apslēpta sarežģītā juridiskā valodā, vai nav atzīmējuši īpašus noteikumus, kuri precīzi neatbilst iepriekš definētām kategorijām. Tomēr jaunākie tehniskie risinājumi (Retrevial Augmented Generation) atrisina lielāko daļu šo problēmu. Pastāv arī satraucoša iespēja, ka šos modeļus var maldināt ar apzināti neskaidras valodas palīdzību, modelim potenciāli nepamanot kritiskus aspektus veikli formulētos dokumentos. Pašlaik attīstās ievērojama adversārās (pretnostatījuma) žurnālistikas pētniecības joma, tāpat kā attēlu apstrāde, kuru mērķis ir padarīt noteiktus datu šablonus mašīnām grūti atklājamus.
Kā to uzsvēru arī savas vieslekcijas laikā, Lielie Valodas modeļi būtībā ir sarežģītas datu šablonu atpazīšanas sistēmas. Tie patiesībā pilnībā „neizprot” juridiskos jēdzienus tādā veidā, kā to dara cilvēks – tiesību speciālists, bet tie prognozē visticamāko tekstu, pamatojoties uz datu šabloniem, kas novēroti tā izmantotajos datos, līdzīgi kā tiesību speciālists varētu pabeigt kolēģa teikumu, balstoties uz kopīgām zināšanām par juridisko žargonu. Šis fundamentālais ierobežojums nozīmē, ka modeļi dažreiz var ģenerēt ticamu, bet nepareizu informāciju, īpaši saskaroties ar jauniem vai sarežģītiem juridiskiem jautājumiem.
Šie modeļi arī rada nozīmīgas ētiskas un privātuma bažas. Milzīgais datu apjoms, kas nepieciešams to apmācībai, var ietvert jutīgu vai privileģētu informāciju, radot jautājumus par konfidencialitāti un datu aizsardzību.
Uzlabotie valodas modeļi jau piedāvā jaudīgas spējas, kas sniedz taustāmus ieguvumus juridiskajam darbam, sākot no pētniecības un dokumentu pārskatīšanas optimizēšanas, līdz līgumu analīzes un sastādīšanas uzlabošanai. Šīs tehnoloģijas ir pierādījušas savu spēju palielināt efektivitāti, samazināt izmaksas un uzlabot precizitāti dažādos juridiskos uzdevumos. Lai gan konkrētās priekšrocības kļūst acīmredzamas, nepārtraukta eksperimentēšana un rūpīga novērtēšana joprojām ir nepieciešama, lai pilnībā izprastu un mazinātu potenciālos riskus.
Šie rīki strauji pilnveidojas, paplašinot uzdevumu sarakstu, ko tie var paveikt vismaz tikpat labi kā tiesību speciālisti. Tomēr kopumā pareizi būtu uzskatīt tos par gudriem palīglīdzekļiem cilvēka zināšanu papildināšanai, nevis aizstāšanai, līdzīgi kā juridiskās datubāzes un meklētājprogrammas ir kļuvušas par neaizstājamiem, bet papildinošiem rīkiem kvalificētiem tiesību profesionāļiem. Juridiskā profesija var gūt labumu, aktīvi izmantojot šīs tehnoloģijas, paļaujoties uz to priekšrocībām, vienlaikus apzinoties to trūkumus. Šī atvērtā un aktīvā pieeja ļaus izstrādāt labākās piemērošanas prakses un ētikas vadlīnijas, kas nodrošinās, ka juridiskie pamatprincipi paliek jurisprudences centrālais elements. Šodienas ieguvumi noliec svaru kausus par labu nepieciešamībai pēc inovācijām juridiskajā jomā. Tiesību integritātes un uz cilvēku centrēts raksturs nodrošinās, ka iespējamie riski tiks pienācīgi pārvaldīti.


 QR
QR